|
I am a Senior Staff Research Scientist at Google DeepMind in the Open-Endedness team. I am also an Honorary Lecturer (Adjunct Professor) at UCL, working closely with the UCL-DARK Lab where I advise PhD students. I also co-developed and am currently co-teaching a new course on Open-Endedness and General Intelligence. Previously, I was a Research Scientist at Meta GenAI where I led the AI Scientist team. Our goal was to accelerate AI Research and Development using AI Agents that can generate ideas and hypotheses, implement new methods, train ML models, run experiments, analyze results, and iterate through this process to make new scientific discoveries. At Meta, I also started and led the Tool Use team for Llama 3. This enabled Llama to use tools such as a search engine, Python interpreter, text-to-image models, and Wolfram Alpha, as well as zero-shot generalize to new tools at test time. Our research on LLM Agents enabled new products used my hundreds of millions of users such as Meta AI, Data Analyst, AI Studio, and the Ads Business Agent. In 2021, I obtained my PhD in Computer Science from NYU, advised by Rob Fergus. My focus was on deep reinforcement learning. During my PhD, I was fortunate to intern at DeepMind, Microsoft Research, and Facebook AI Research. Previously, I obtained a B.A. in Astrophysics from Princeton University, where I worked with Michael Strauss on theoretical cosmology and Eve Ostriker on supernovae simulations. In a past life (aka high school), I was fortunate to have the opportunity of competing in IPhO, IOAA, IAO, as well as national math and computer science olympiads. |

|
|
I am broadly interested in designing machine learning algorithms that can make robust sequential decisions in complex environments, while constantly acquiring new skills and knowledge. My long-term goal is to develop models that can solve a wide range of new tasks with little or no supervision and training. I also care deeply about ensuring such systems are reliable, trustworthy, and aligned with human intentions. My work draws from fields such as reinforcement learning, open-ended learning, self-supervised learning, and natural language processing. Currently, I work at the intersection of large language models (LLMs) and decision making / RL. In particular, I focus on augmenting LLMs with decision making abilities (e.g. planning, reasoning, actions, tools, and goals), and teaching them to learn from (human) feedback and interaction in an open-ended learning fashion. I'm also interested in understanding and improving the generalization and robustness of autonomous agents and large pretrained models. In the past, I've worked on deep reinforcement learning, exploration, fast adaptation, learning from demonstrations, as well as continual and multi-agent learning. |
|
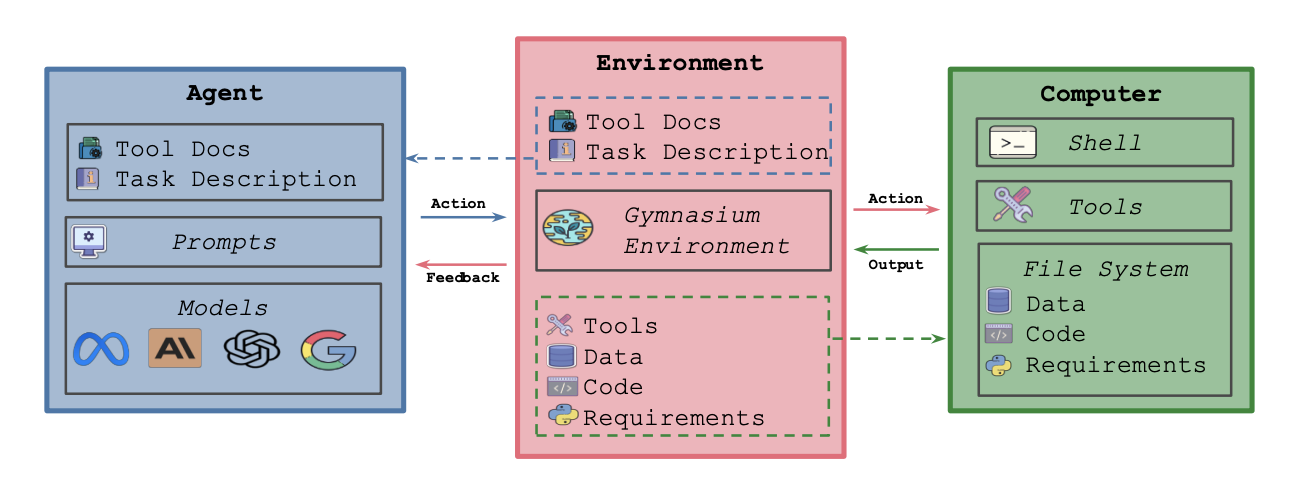
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens, Amar Budhiraja, Despoina Magka, Vladislav Vorotilov, Gaurav Chaurasia, Dieuwke Hupkes, Ricardo Silveira Cabral, Tatiana Shavrina, Jakob Foerster, Yoram Bachrach, William Yang Wang, Roberta Raileanu arXiv, 2025 paper / code / website A new framework and benchmark to accelerate AI Research and Development using AI Agents. |
|
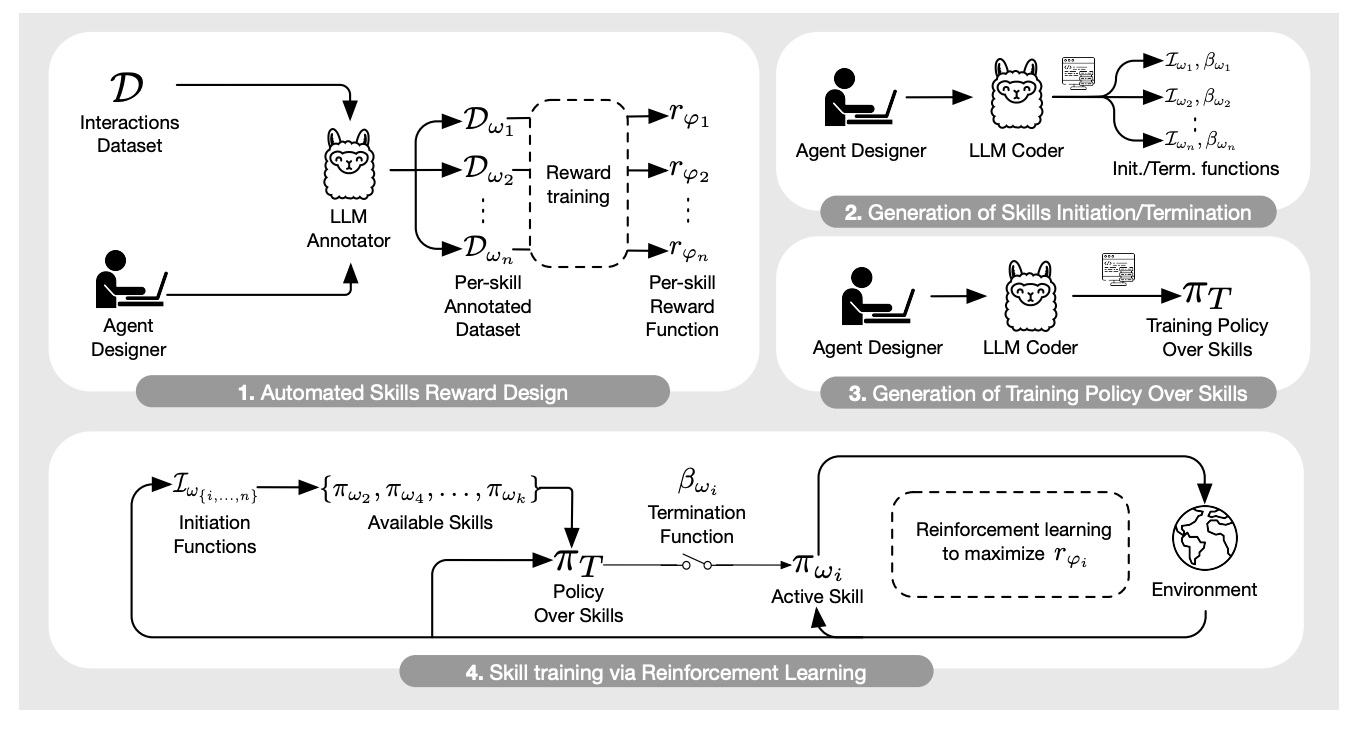
Martin Klissarov, Mikael Henaff, Roberta Raileanu, Shagun Sodhani, Pascal Vincent, Amy Zhang, Pierre-Luc Bacon, Doina Precup, Marlos C. Machado, Pierluca D'Oro arXiv, 2025 paper / code Introduce MaestroMotif, a new method for training hierarchical LLM agents to solve complex compositional tasks requiring hundreds of steps. |
|
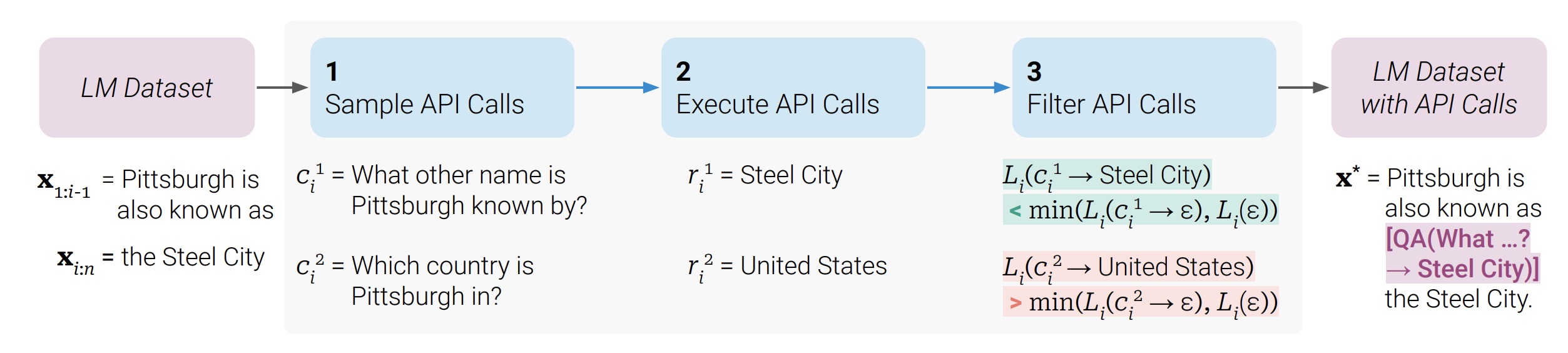
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom arXiv, 2023 paper A method that teaches language models to use tools in a self-supervised way. |

|
Grégoire Mialon et al. arXiv, 2023 paper Survey on augmenting language models with reasoning, actions, and tool use. |
|
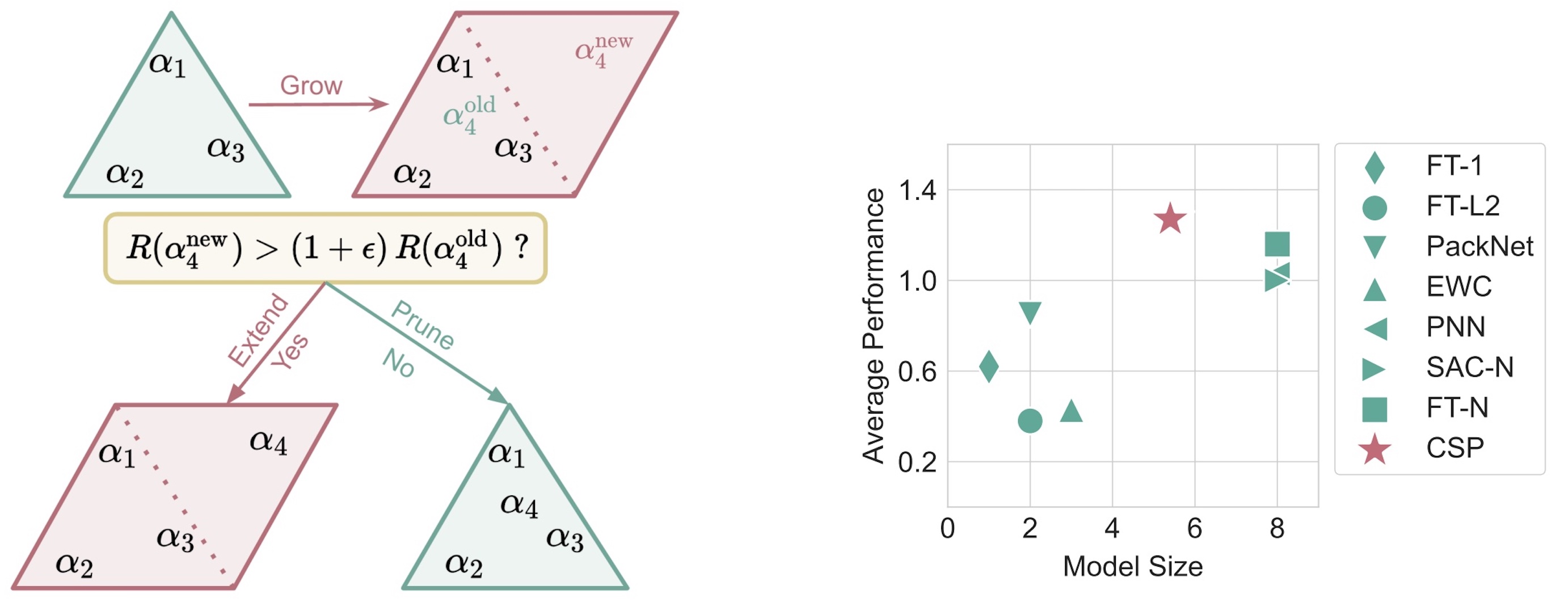
Jean-Baptiste Gaya, Thang Doan, Lucas Caccia, Laure Soulier, Ludovic Denoyer, Roberta Raileanu ICLR, 2023 (spotlight, top-25%) paper Introduce a continual reinforcement learning method that incrementally builds a subspace of policies and adaptively prunes it to preserve a good trade-off between model size and performance. |
|
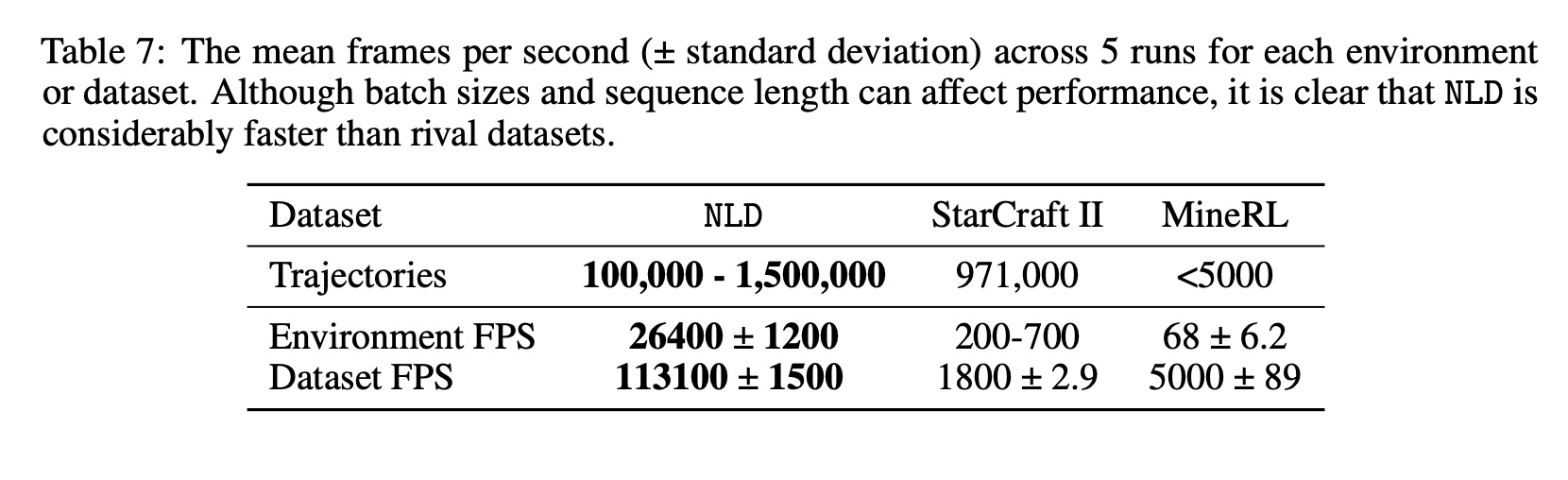
Eric Hambro, Roberta Raileanu, Danielle Rothermel, Vegard Mella, Tim Rocktäschel Heinrich Küttler, Naila Murray NeurIPS, 2022 paper / code Present the NetHack Learning Dataset (NLD), a large and highly scalable dataset of human and bot trajectories on the popular game of NetHack. |

|
Mikael Henaff, Roberta Raileanu, Minqi Jiang, Tim Rocktäschel NeurIPS, 2022 paper / code / website Extend episodic count-based bonuses to continuous state spaces for better exploration of contextual MDPs with high-dimensional observations. |
|
Jesse Mu, Victor Zhong, Roberta Raileanu, Minqi Jiang, Noah Goodman, Tim Rocktaschel, Edward Grefenstette NeurIPS, 2022 paper Using language to highlight relevant state abstractions leads to better exploration in sparse reward procedurally generated environments. |

|
Open Ended Learning Team, Adam Stooke, Anuj Mahajan, Catarina Barros, Charlie Deck, Jakob Bauer, Jakub Sygnowski, Maja Trebacz, Max Jaderberg, Michael Mathieu, Nat McAleese, Nathalie Bradley-Schmieg, Nathaniel Wong, Nicolas Porcel, Roberta Raileanu, Steph Hughes-Fitt, Valentin Dalibard, Wojciech Marian Czarnecki paper Training agents on dynamically changing task distributions leads to more general agents capable of solving a wide range of tasks in procedurally generated environments. |
|
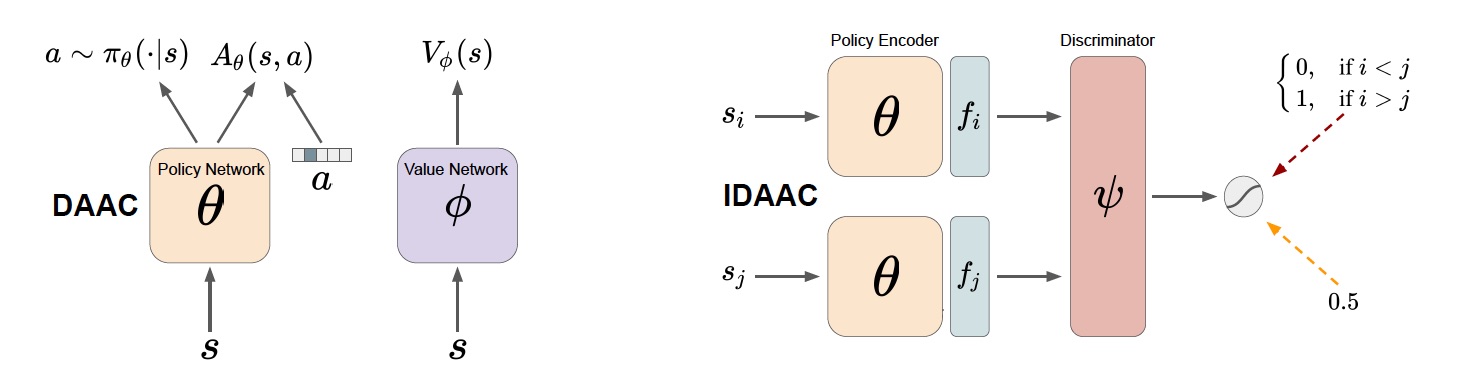
Roberta Raileanu, Rob Fergus ICML, 2021 (oral) paper / code Using a common representation for the policy and value function can lead to overfitting in deep reinforcement learning. To improve generalization, use the advantage instead of the value as auxiliary loss to train the policy network, while encouraging the representation to be invariant to task-irrelevant properties of the environment. |
|
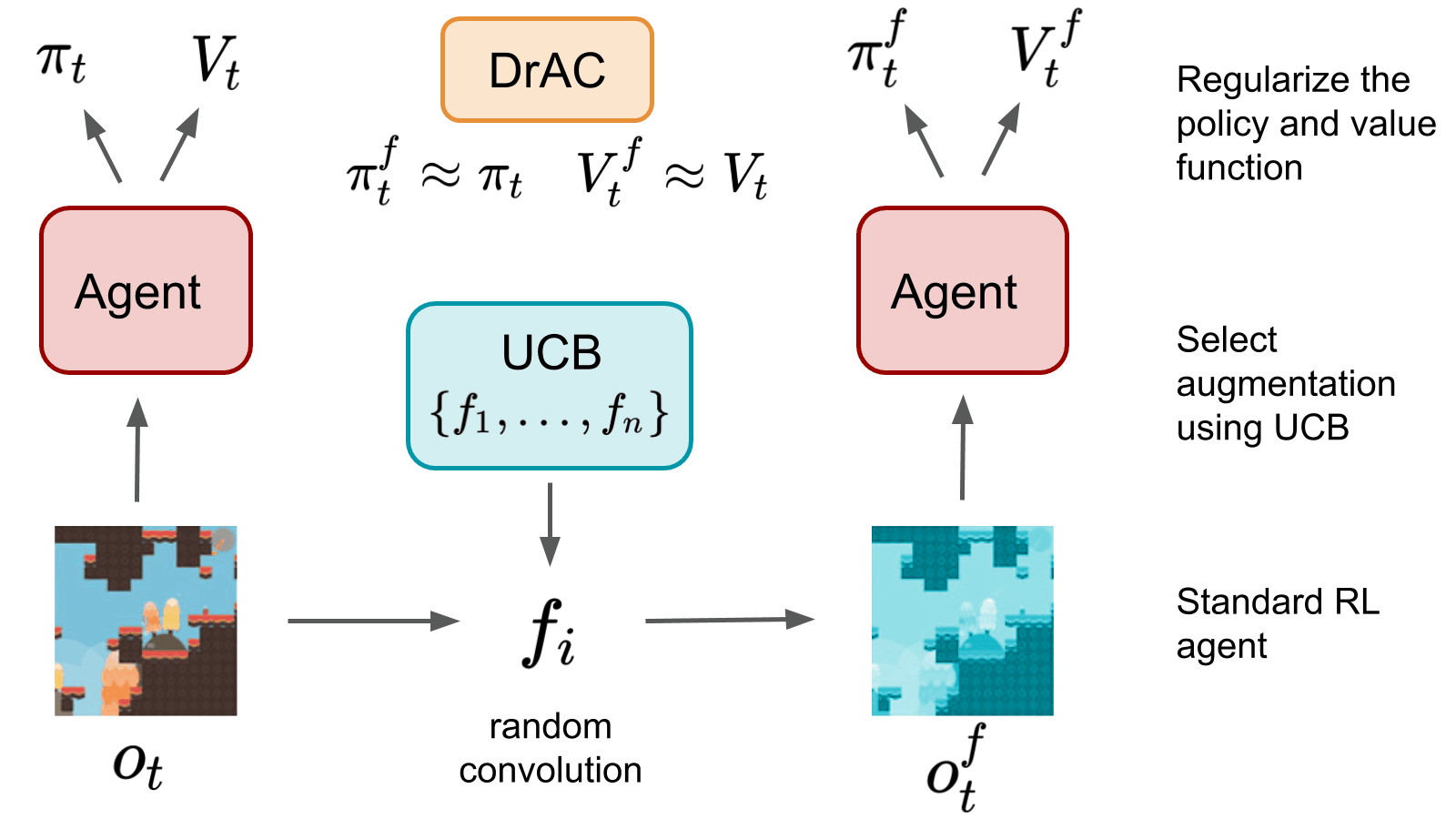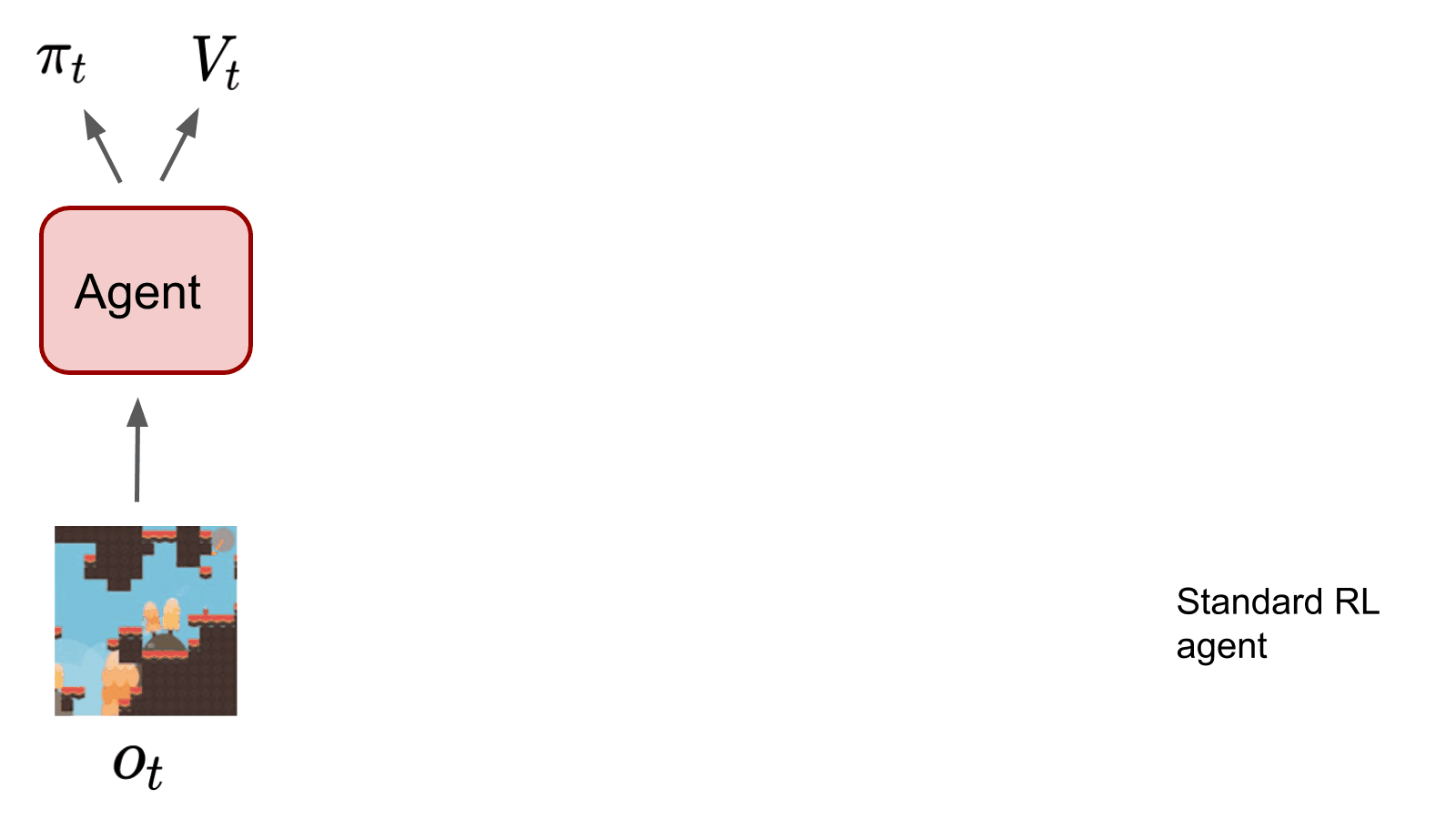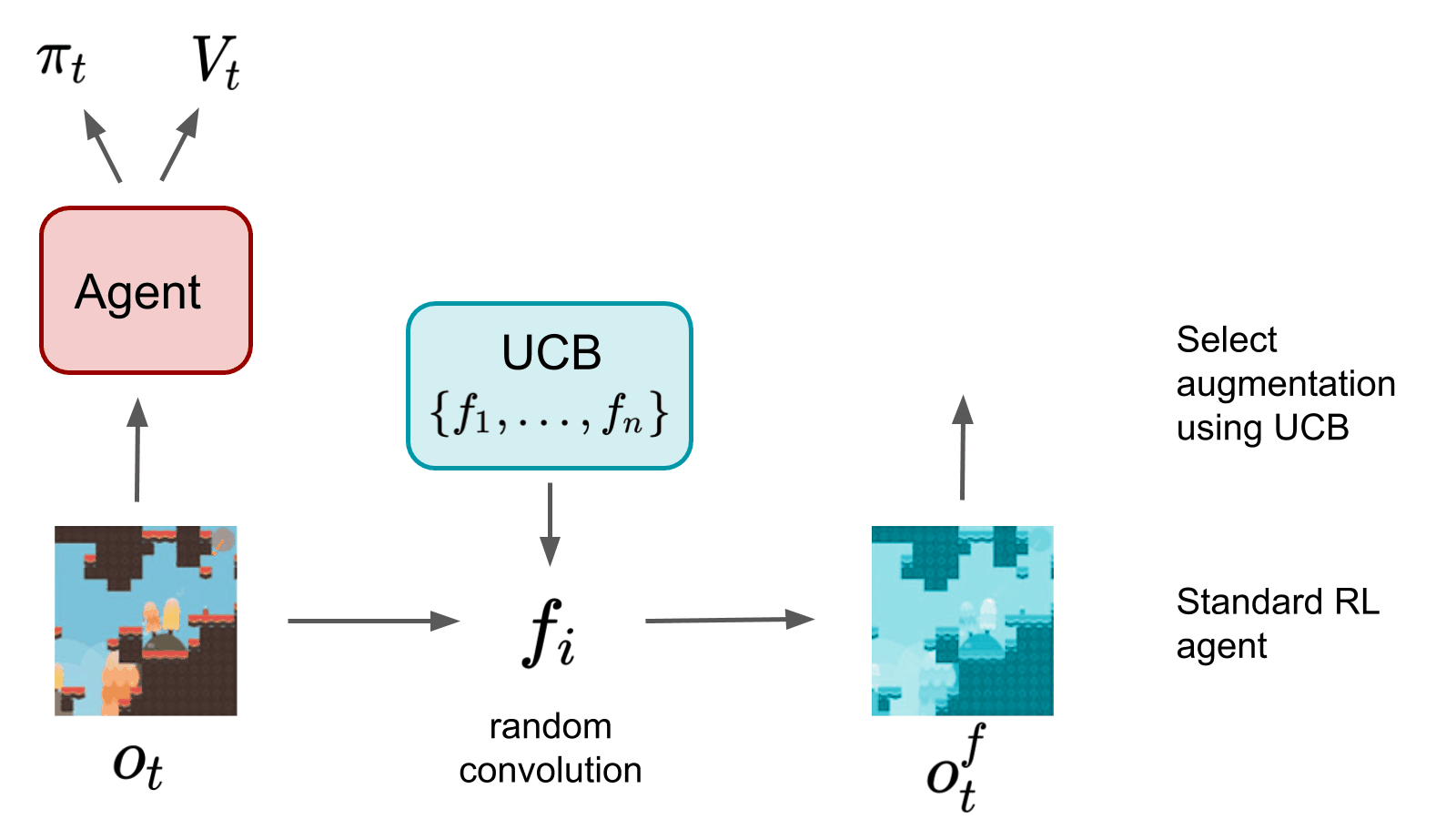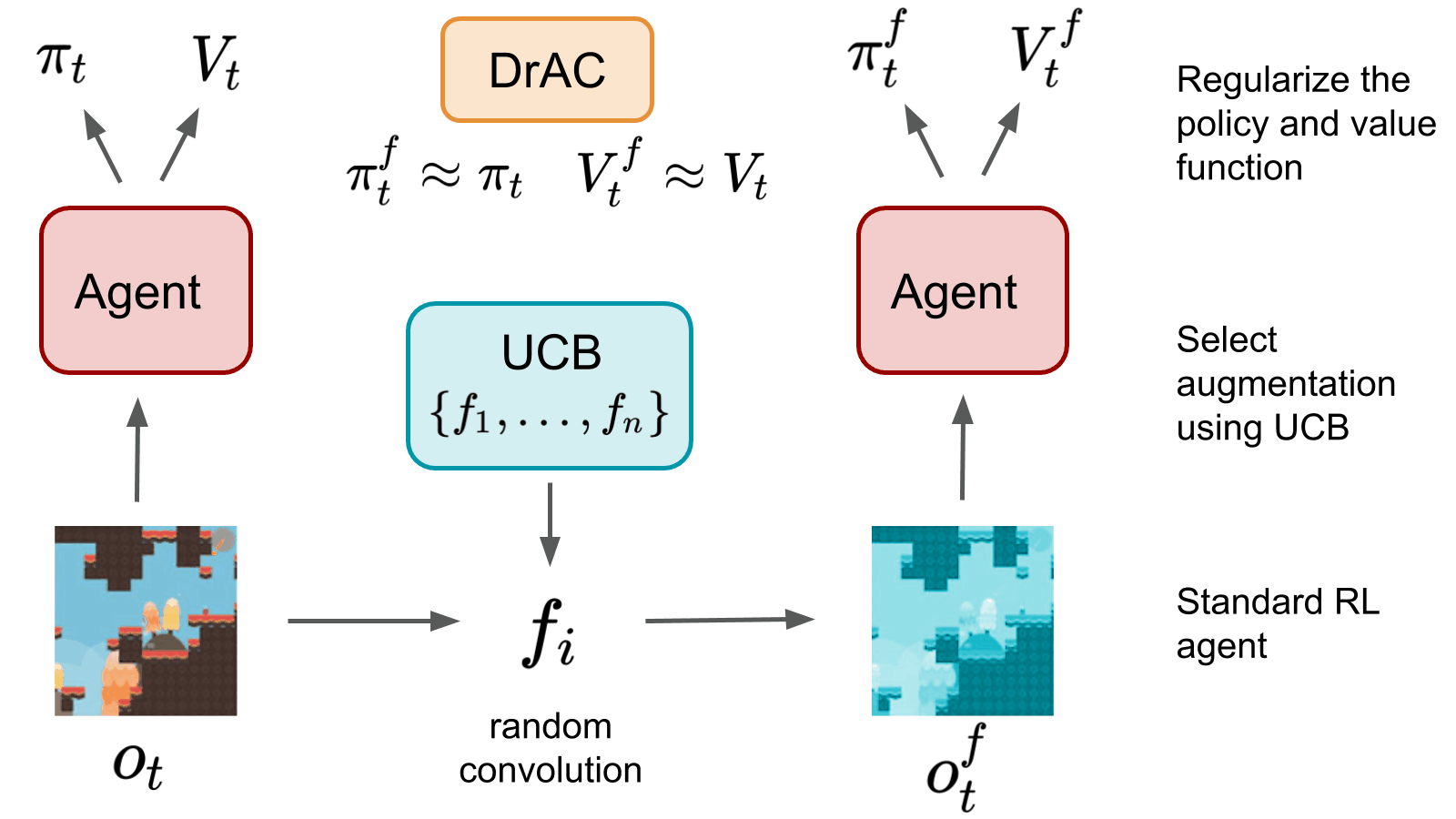
Roberta Raileanu, Max Goldstein, Denis Yarats, Ilya Kostrikov, Rob Fergus NeurIPS, 2021 Inductive Biases, Invariances and Generalization in RL (BIG) Workshop, ICML, 2020 (oral) paper / code / slides / website Use UCB to automatically select an augmentation from a given set, which is then used to regularize the policy and value function of an RL agent. |
|
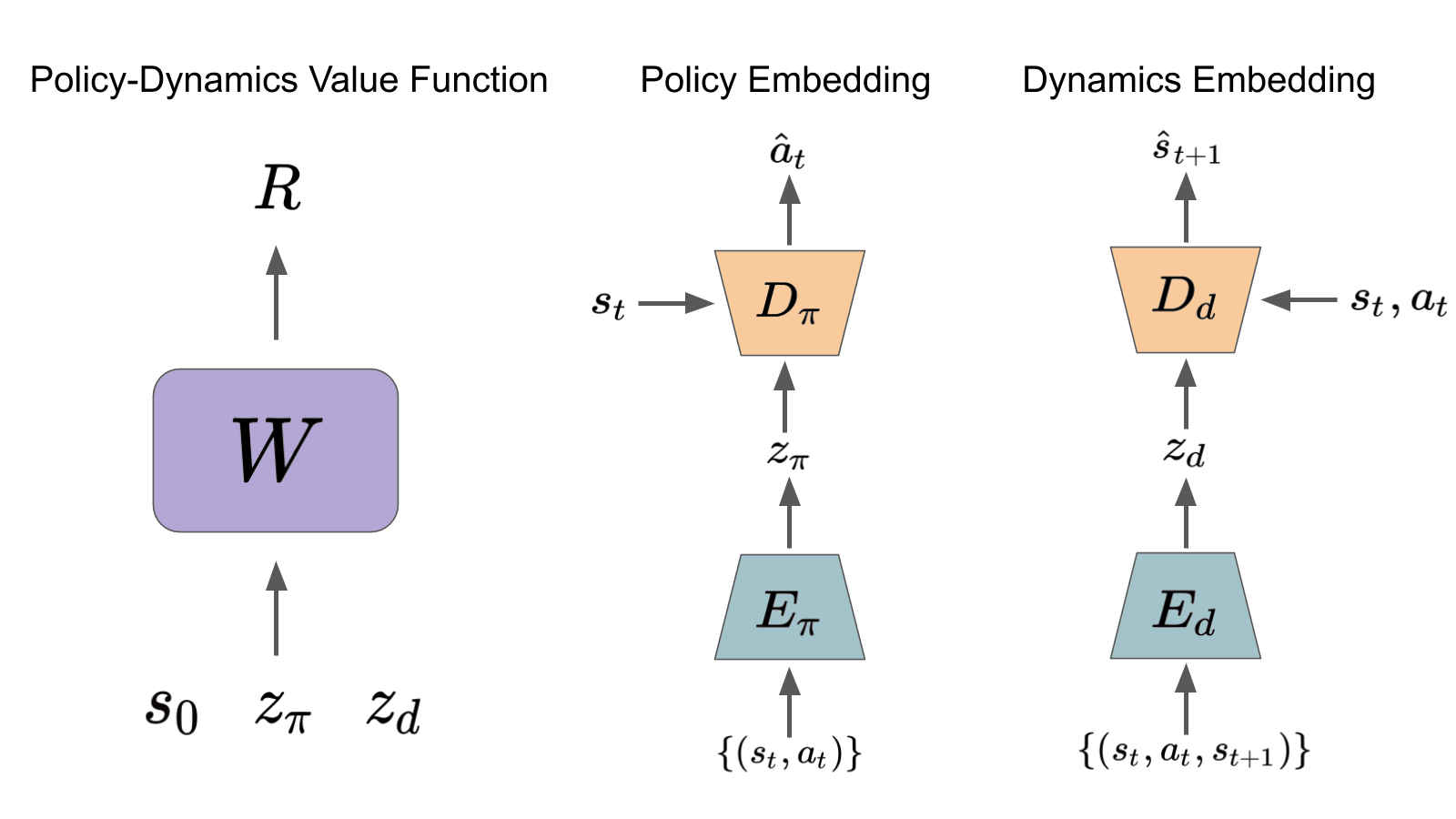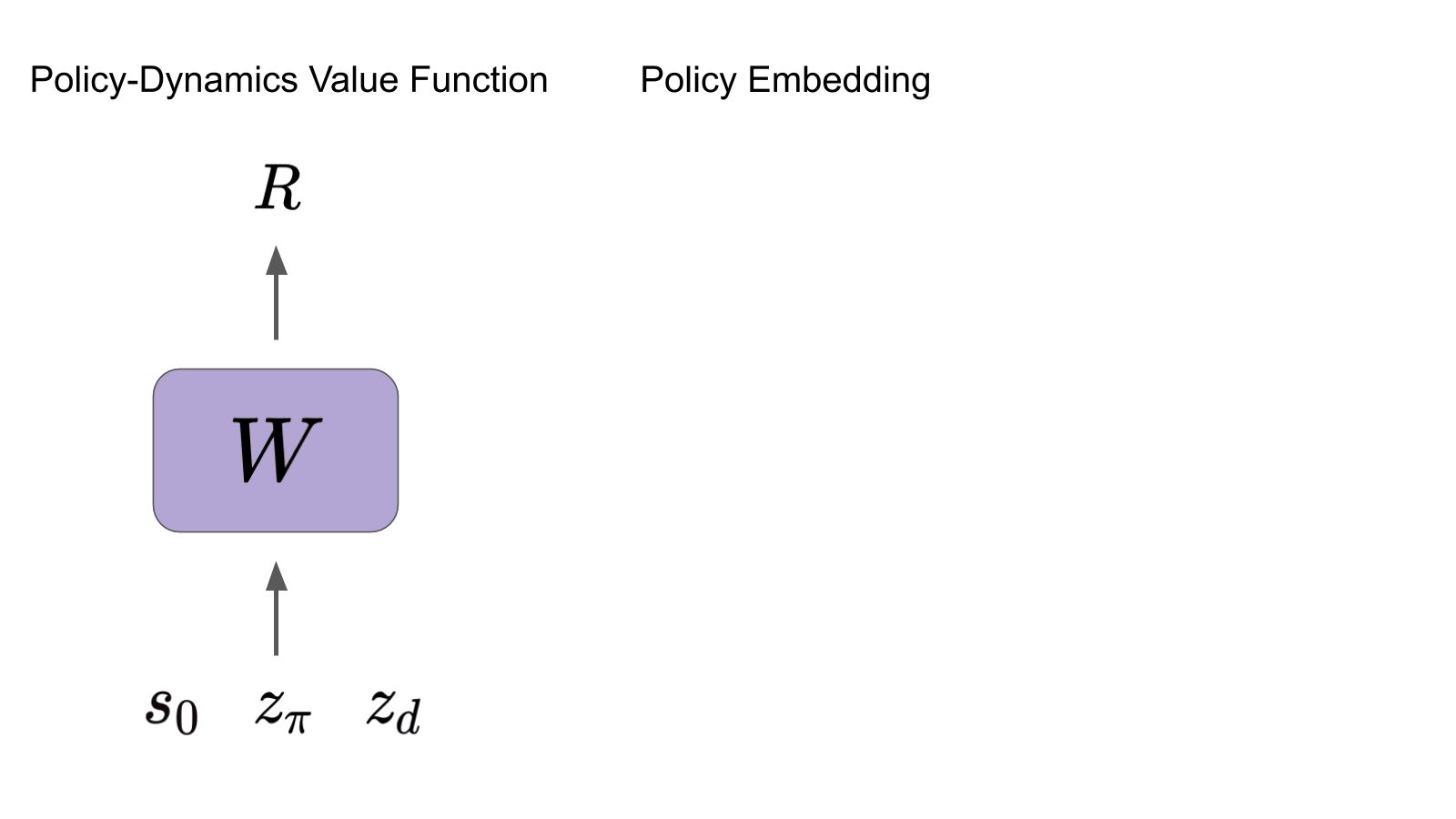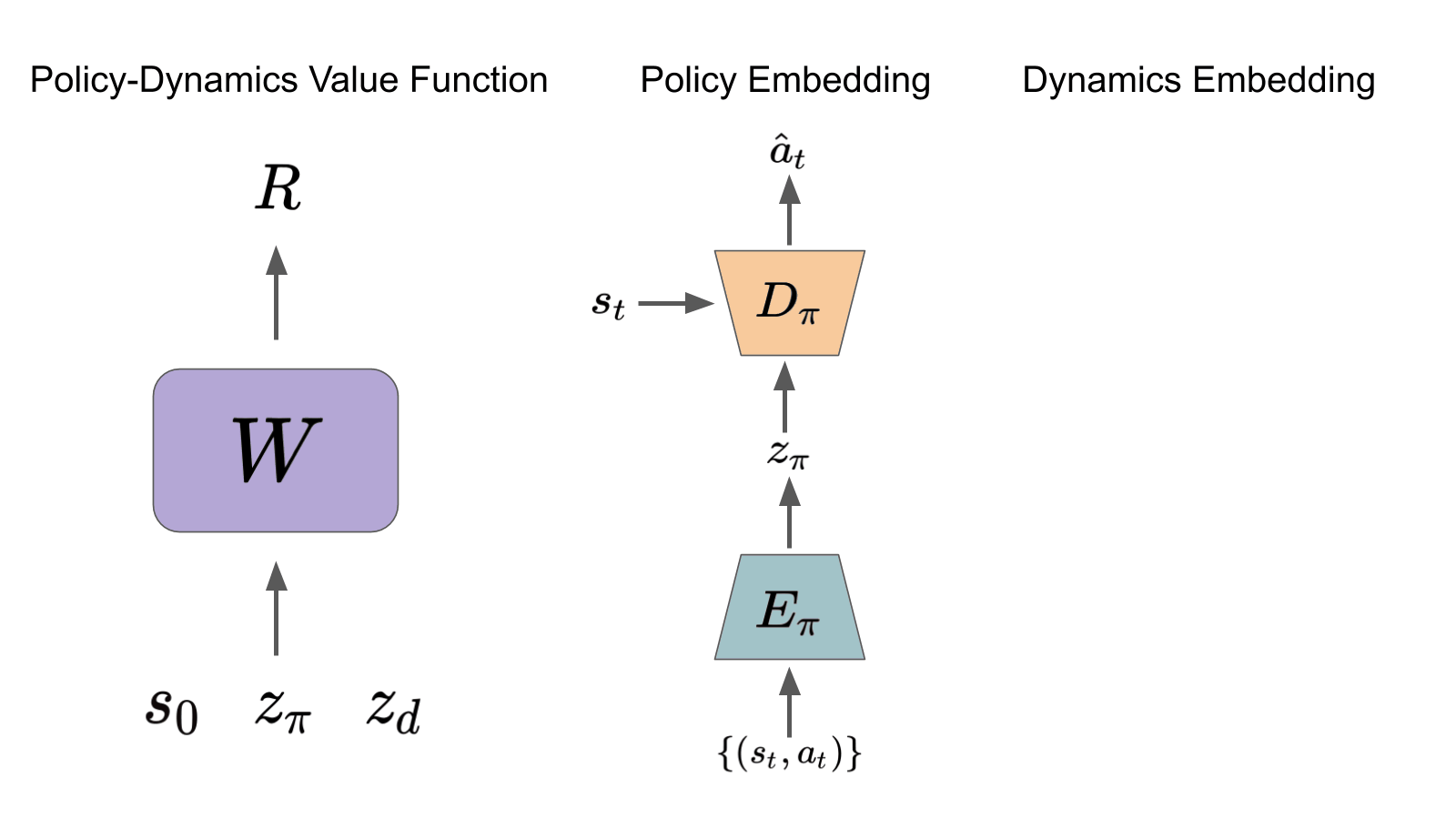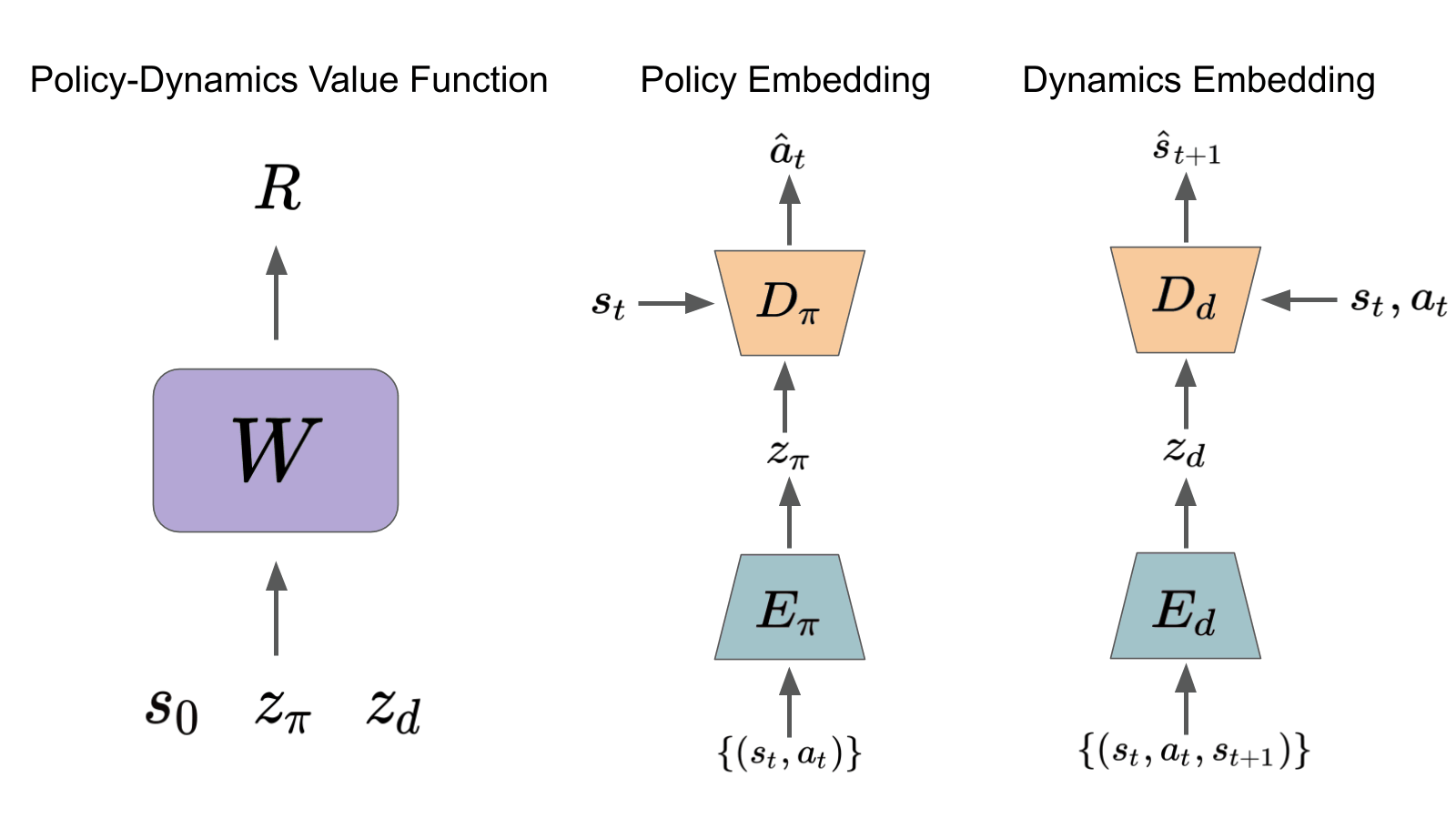
Roberta Raileanu, Max Goldstein, Arthur Szlam, Rob Fergus ICML, 2020 Beyond "Tabula Rasa" in Reinforcement Learning (BeTR-RL) Workshop, ICLR, 2020 (oral) paper / code / slides / website Learn a value function for a space of policies and environments (with different dynamics) and use it for fast adaptation in new environments with unseen dynamics. |
|
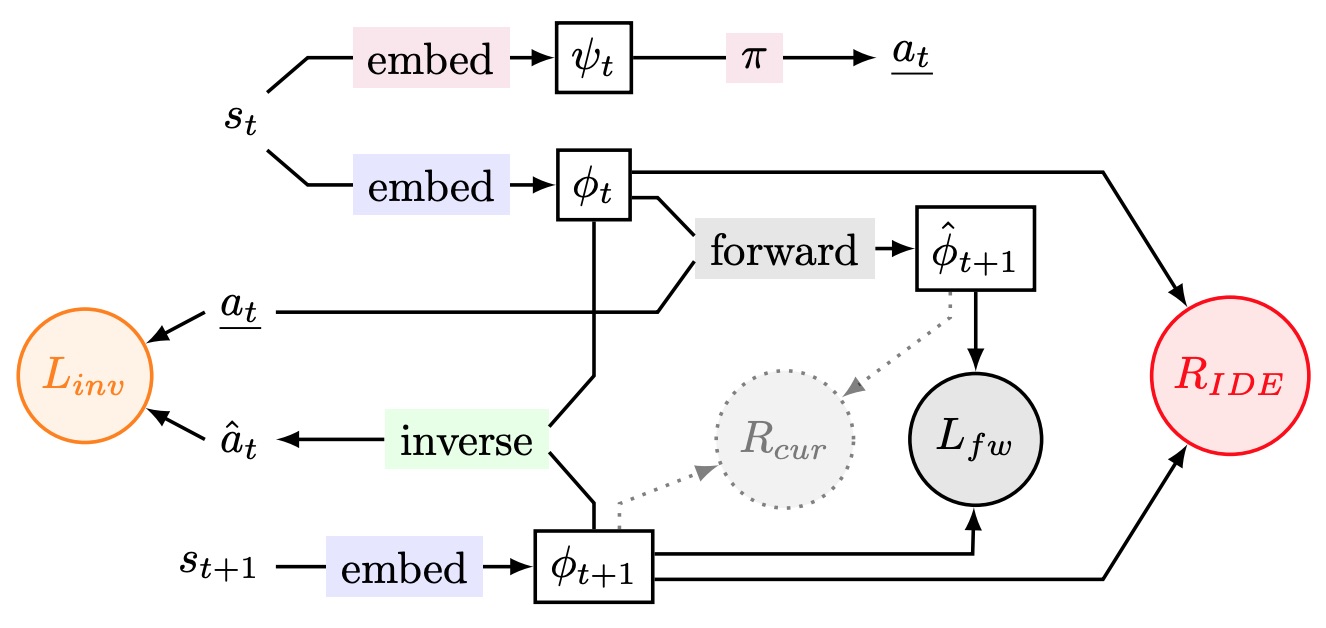
Roberta Raileanu, Tim Rocktäschel ICLR, 2020 paper / code / slides Reward agents for taking actions that lead to large changes in the environment and for visiting new states within an episode. |

|
Heinrich Küttler, Nantas Nardelli, Alexander H. Miller, Roberta Raileanu, Marco Selvatici, Edward Grefenstette, Tim Rocktäschel NeurIPS, 2020 Beyond "Tabula Rasa" in Reinforcement Learning (BeTR-RL) Workshop, ICLR, 2020 paper / code / slides The NetHack Learning Environment (NLE) is a fast, procedurally generated, stochastic, rich, and challenging environment for RL research based on the popular game NetHack. |
|
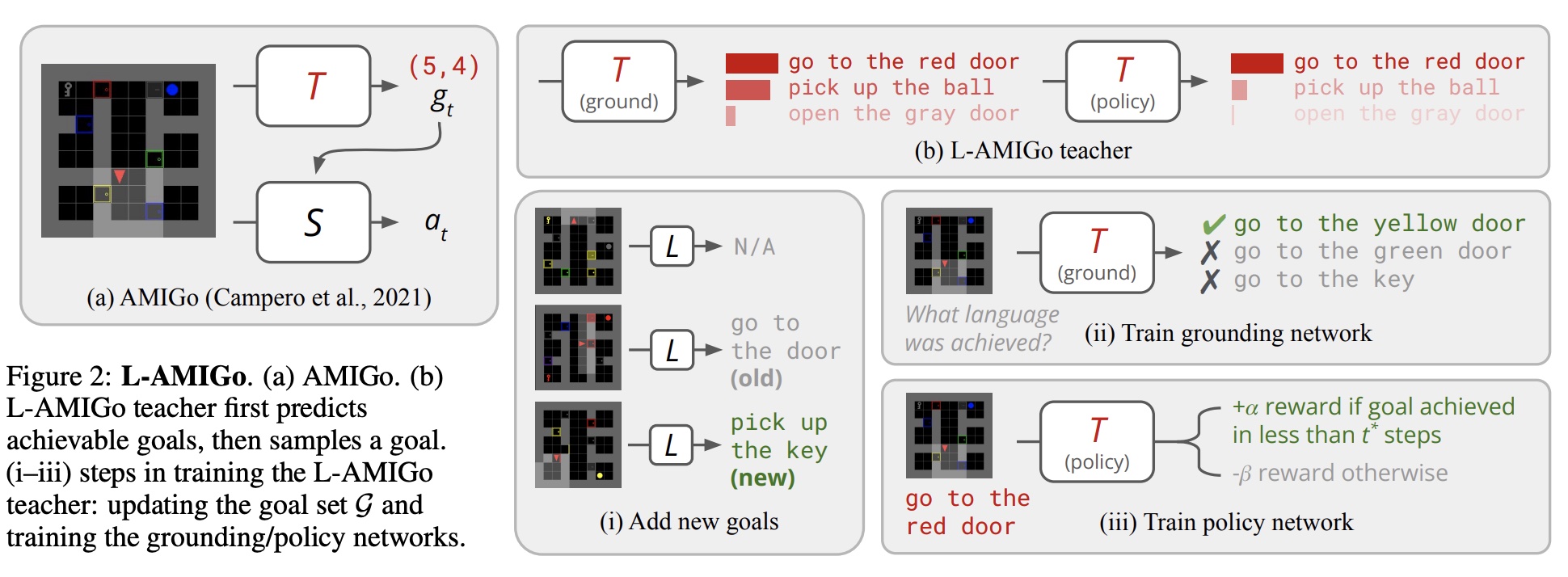
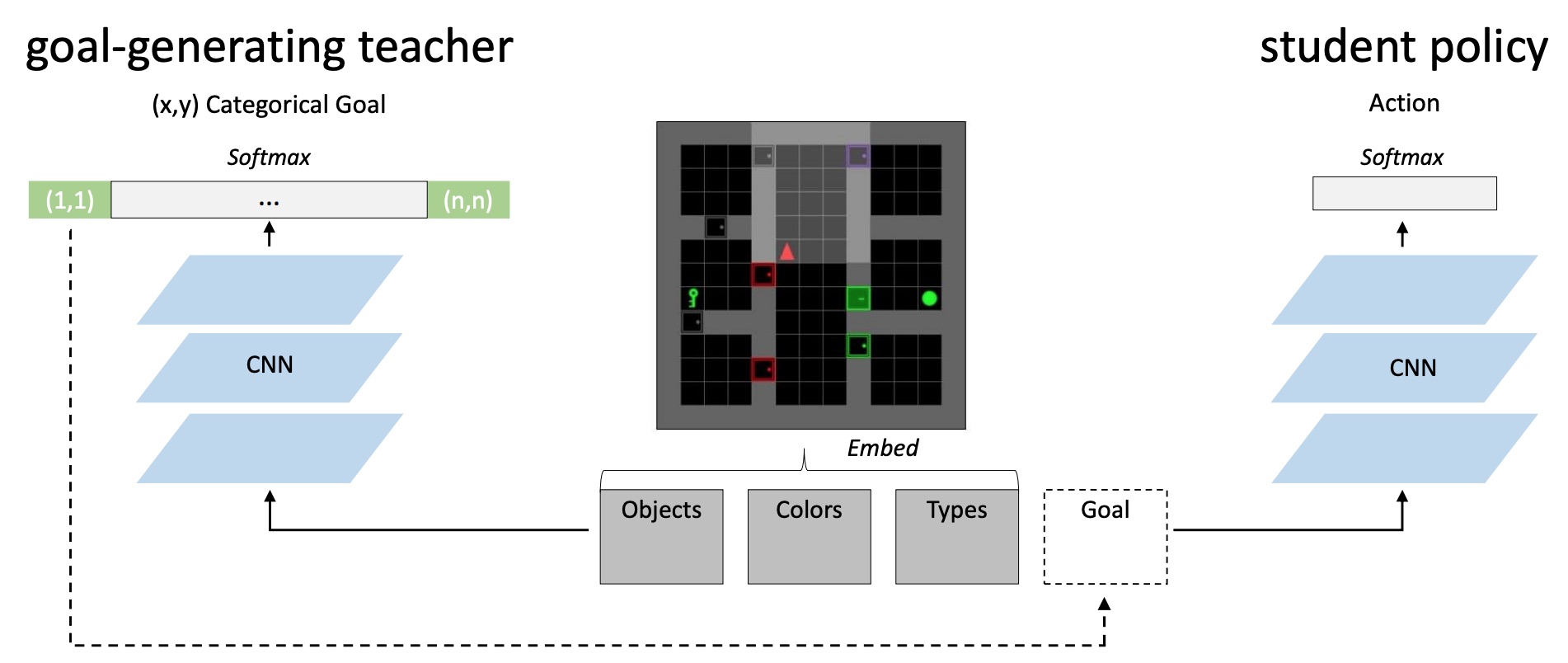
Andres Campero, Roberta Raileanu, Heinrich Küttler, Joshua B. Tenenbaum, Tim Rocktäschel, Edward Grefenstette, ICLR, 2021 paper / code A teacher learns to generate goals at an appropriate level of difficulty for a student, creating an automatic curriculum that aids exploration. |
|
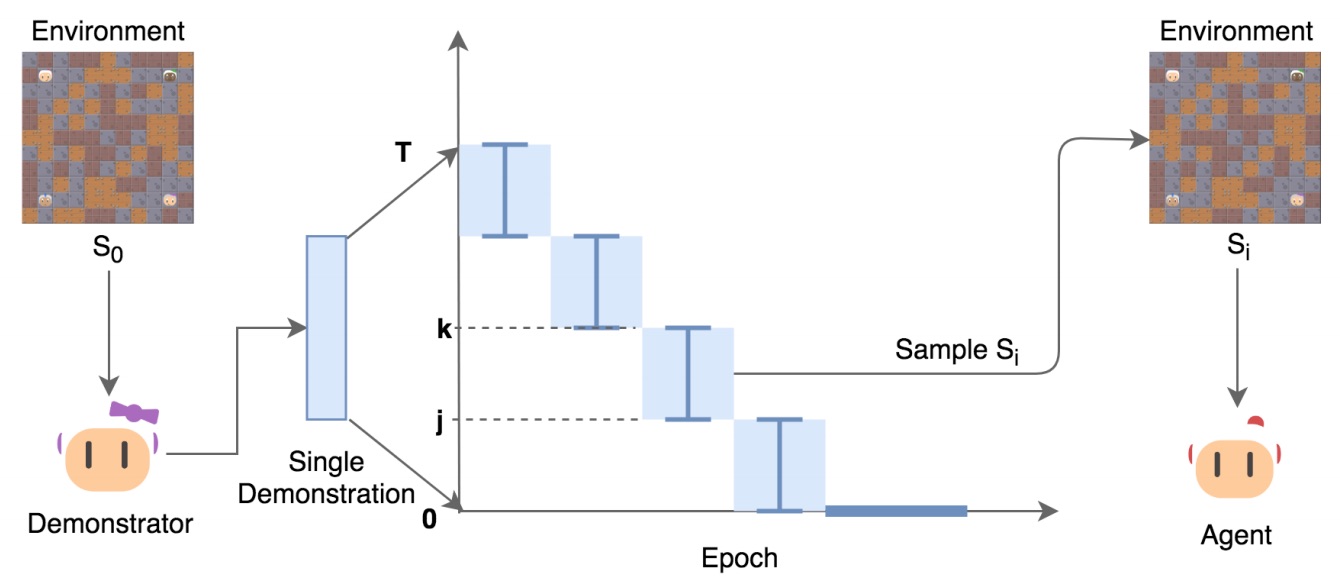
Cinjon Resnick*, Roberta Raileanu*, Sanyam Kapoor, Alexander Peysakhovich, Kyunghyun Cho, Joan Bruna Reinforcement Learning in Games Workshop, AAAI, 2019 paper / slides Create a curriculum by initializing the RL agent along a single demonstration (either optimal or suboptimal) starting near the end of the trajectory. |
|
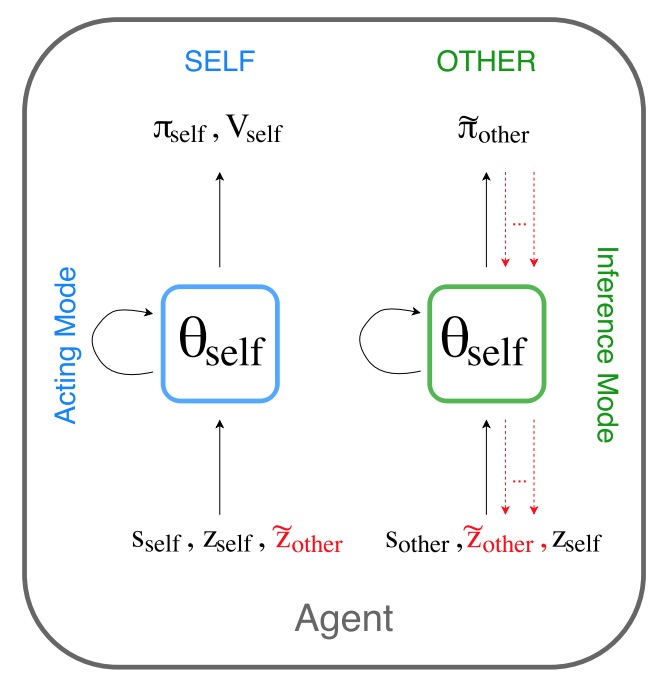
Roberta Raileanu, Emily Denton, Arthur Szlam, Rob Fergus ICML, 2018 Emergent Communication Workshop, NeurIPS, 2017 paper / slides Simulate other agents' behavior and infer their intentions by using your own policy. |
|
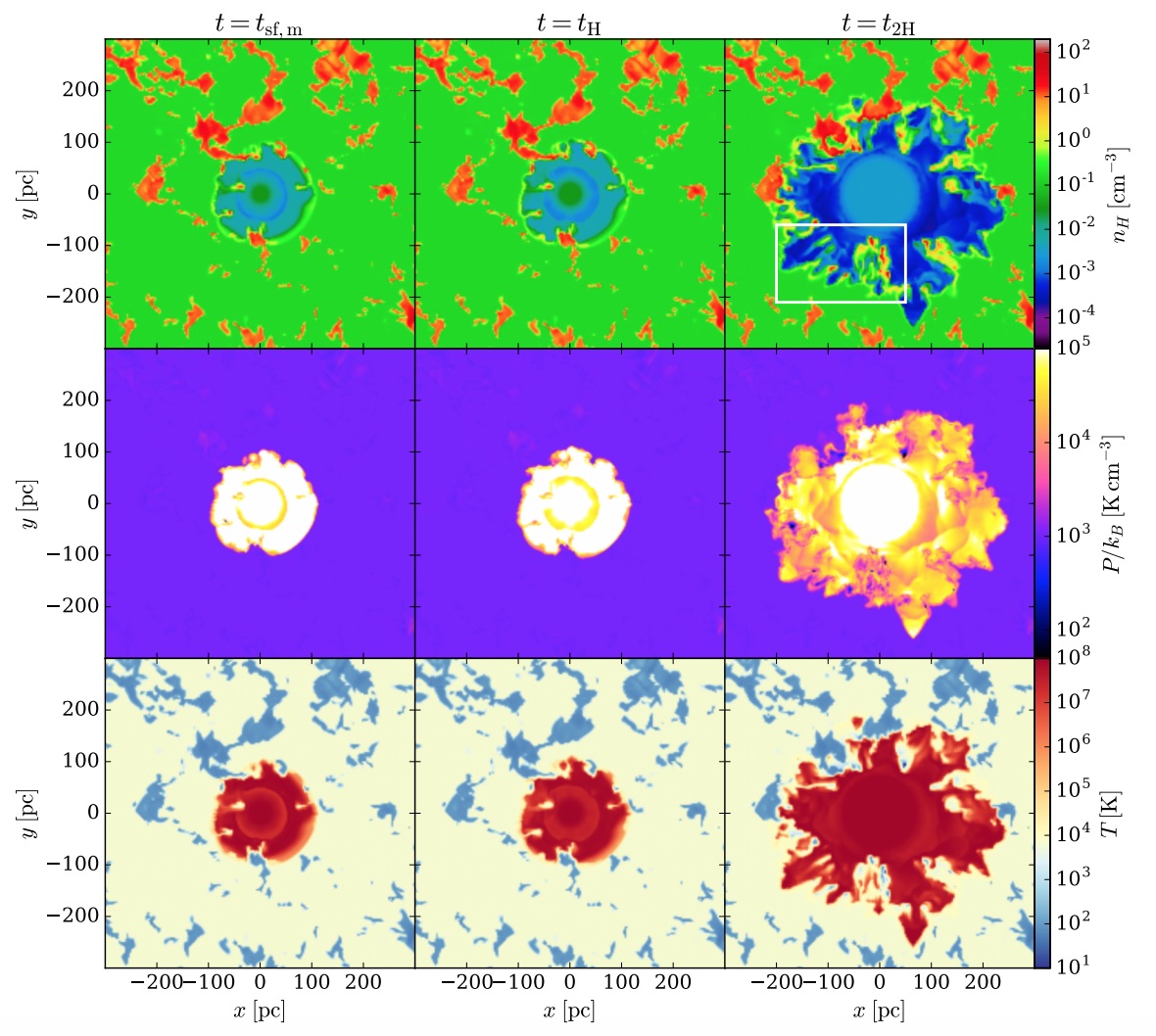
Chang-Goo Kim, Eve C. Ostriker, Roberta Raileanu, The Astrophysical Journal, 2016 paper Use numerical simulations to analyze the evolution and properties of superbubbles, driven by supernovae, that propagate into the two-phase, cloudy interstellar medium. |
|
|